
I don’t usually post news like this but I found it extremely interesting that a class action lawsuit has been filed against Seagate regarding their lately criticized hard drives.
Essentially, a complaint has been filed calling attention to the fact that Seagate has been producing drives that have had less than stellar reliability. In fact, much of the claim is based on the data that Backblaze has compiled in addition to general user experience and RMA/return demographics.
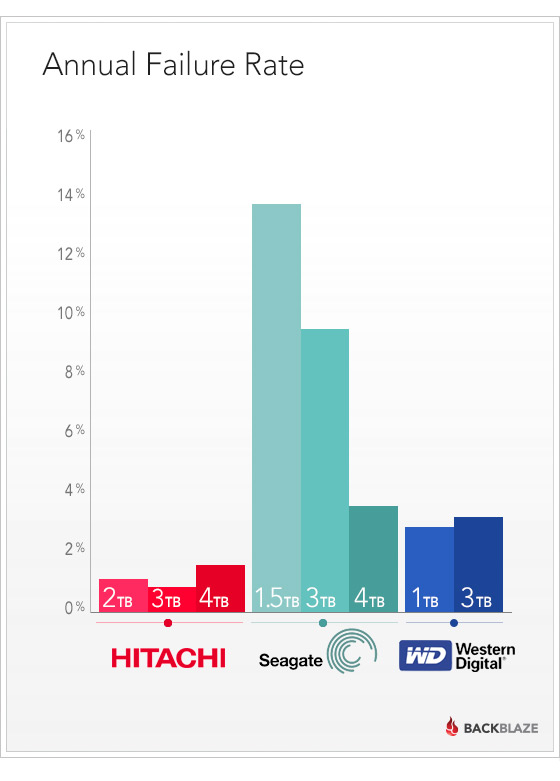
As someone who follows the storage industry pretty closely I do tend to steer friends and colleagues away from Seagate when it comes to hard drive recommendations. Sometimes I feel bad about this because there are deals to be had by using Seagate spindles and I haven’t really had any bad experiences of my own (if you discount the several failures I experienced with the cursed first round of Seagate 1.5TB drives many years ago). However, when Backblaze started tracking their MTBF figures between various manufacturers it was then that I felt like there may be weight to my opinion. In fact, when I built the storage in my ESXi server that serves up this website I ended up choosing Western Digital 4TB Red drives specifically because of the Backblaze study:
So, why a class action lawsuit? Well, probably because Seagate, like all manufacturers, go out of their way to highlight the reliability and dependability of their drives. It’d be silly to expect them to not market their products in this manner – the gripe is that they’ve missed the mark so, so bad. That’s not to say that some Seagate products are not OK – some people have success with them. The reality of the situation is that hard drives fail all the time but most manufacturers will do their best to try and hone in on the issue and resolve the problem in order to protect their brand.
For instance, after the tsunami hit Japan a few years ago, Western Digital had a hard time continuing their manufacturing schedule with all of the flooding in Thailand. As a result production numbers suffered. Western Digital could have sent their manufacturing out-of-house for a time while they recover from flooding but they didn’t think they could maintain production level/quality while doing so. It would seem as if Seagate just marches forward without regard to resolution; as if they feel that they can continue to churn out spindles and perhaps the problem will just resolve itself.
I try to not get too confident in my ability to assess the situation, but I’ve been “computing” for a long time. In fact, I had a Western Digital 85MB IDE hard drive in my basement (am I dating myself?) for ages. That said, 3.1GB, 30GB, 60GB, even 250GB drives have always failed – failure is nothing new. What is new, however, is drive capacity going from 4TB, 6TB, and 8TB with 10TB units right around the corner. Today, when a drive fails, you’re not losing the OS, a dozen applications, and some personal documents. Instead, you’re losing literally all of your digital belongings – potentially years and years of photos, music, converted and home movies, etc. Worse yet is that many people are running 4TB and 6TB drives in various forms of parity-based RAID.
While parity-based RAID with such large drives will offer you redundancy it does introduce a new issue into the mix: rebuilding the array can take so long that another drive can fail during the operation. Oh no! So, while you are protecting yourself from catastrophic data-loss if a single disk fails, you’re also not in the clear until the array successfully rebuilds. This is something I’ve come to accept while running an eight-disk RAID 50 configuration with 4TB drives in one of my personal servers.
One of the most interesting articles I’ve read regarding storage of big data was of an engineer at Google suggesting storage engineers consider RAID 0 to management so as to eliminate the suggestion that an array will rebuild because with huge spindle count and drive capacity it’s very possible it will not rebuild successfully – RAID 0 would quench false hope. Instead, the article stresses that data should be protected by replication of the data to many arrays. But, I’m getting off track…
So, while we may focus on drive capacity growing and growing the thing that sneaks by, right under our nose, is the evolution of data-loss. It is for this reason that I can’t really argue with the filer of the class action suit against Seagate – they kind of have something to stand on here. While it might be in the economic best interest of most disk manufacturers to just write off the N hard drive failures as bad luck, it really does seem like Seagate has a pattern that needs to be investigated or at least acknowledged. When your competition has a generally accepted <4% failure rate on a specific size disk and you and have upwards of 10% it might be time to look around and see what’s going on.
“Count on Seagate to deliver the storage innovations that bring down your costs and crank up your storage.” – Seagate Website
Something tells me that Seagate intended to build a reputation around a different interpretation of “crank up your storage.” Either way, it’ll be interesting to see how this filing pans out. I’ll be sure to follow up to this blog entry with whatever comes of the lawsuit!
 I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog!
I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog! 

July 26, 2016
I have had horrific results from seagate 8tb archive drives, I’ve bought six of them and five have failed. THe sixth one hasn’t failed because I haven’t used it yet.
The five that have failed, will fail randomly at any moment and can lose all or part of the hard drive and they have done it several times on each of the drives. I had to go and buy WD red 8TBs to recover what I could.
Is there anyway of getting seagate to replace these drives with a more reliable 8TB drive if they have them.???
March 5, 2016
What is sad is that Seagate has a world class facility in Longmont, CO, and a multi-million dollar investment in test hardware to test, stress, and qualify disk drives. There is simply no excuse for the failures seen in the 1-3TB drives, particularly the 1.5 and 2TB models. It got to the point where you’d look at the ones with a 1 year warranty on the box and wonder if it would actually make it that far. They clearly knew that they had a problem when they reduced the warranty period on most of their consumer drives.
I switched to Hitachi for my critical drive purchases about 5 years ago to replace Seagate, and have always purchased WD Red/Black drives with confidence. Even a few Greens that have taken a beating for three years with no problems. I have had several 1.5 and 2TB Seagate internal and external drives die within the warranty period, and a few just outside.
Vote with your wallet, and move on to Hitachi with WD as a second source for non-enterprise drives. Love to my peeps working in Colorado for Seagate, you do good work but need to establish a five year track record of sub 4% failure rate before I will consider another product purchase.
And, enough, propeller heads. We all know what RAID is, and that it isn’t a backup strategy. You don’t look smart for posting what everyone has known for twenty years.
February 2, 2016
@Dave: Absolutely correct!
RAID = Redundant Array of [Inexpensive/Independent] Disks.
And, the level of redundancy depends on how you configure the RAID. RAID0, as noted above, provides *no* redundancy. RAID6 with one or more hot spares should give sufficient redundancy to protect the data as long as it is monitored to know when one drive fails.
Of course, real redundancy comes from putting critical data on more than one filesystem and/or server. (a.k.a. a Backup)
As my first computer teacher said on the first day of class; “The 3 most important words in Computing are; Backup, backup and BACKUP!”
February 2, 2016
RAID is NOT a backup.
February 2, 2016
Absolutely correct – RAID can add redundancy but it’s not a substitute for proper backups.