
A while back I wrote an article on using vSphere Replication 6 in order to leverage DR/Replication features that are available to you as part of vSphere 6. In that article, I covered the ability to replicate from one vCenter to another but also covered replicating within a single vCenter to separate/different storage available to the environment. At the end of that article I talked about recovering a VM and how there’s no way to replicate just the deltas back to the source vCenter – I also mentioned that to continue re-establish replication of the VM, your only option is to reconfigure replication for the VM on the source vCenter which is only partially accurate.
What I forgot to mention is that you don’t need to start the entire replication over! In fact, it’s pretty simple to recover the VM, turn it on, check that it works, turn it off, and then continue replication without deleting the VM/datastore contents. This blog entry is going to focus on what is needed in order to perform a recovery of a VM while also re-configuring replication while using the existing files on the destination as seeds to continue replication.
This process is necessary because you might have an environment that you’re replicating for DR or maybe planning to migrate to new infrastructure and you want to turn it up and test it and then spin it down but not replicate a ton of data again. In my case I have a couple instances where I want to move a number of large VMs from a source to destination, turn it on, let the application owners test, blow it up, but not have to start from scratch pushing data again.
Below, you can see that we have two VMs being replicated from the source vCenter called krcvc1.krc.local. The status for each VM is “OK” indicating that they’re up-to-date and replicated as required by our RPO settings:
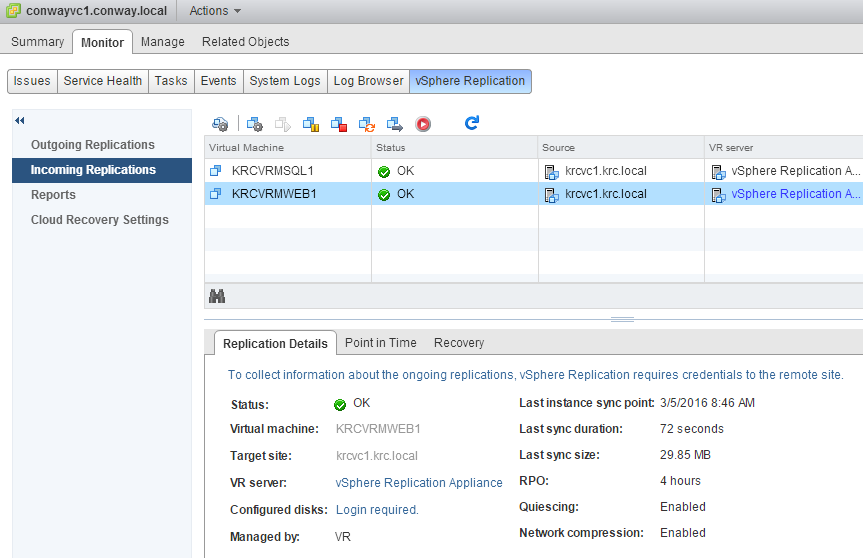
We’ll be testing with the VM named “KRCVRMWEB1” – simply right-click the VM under “Incoming Replications” and choose Recovery…
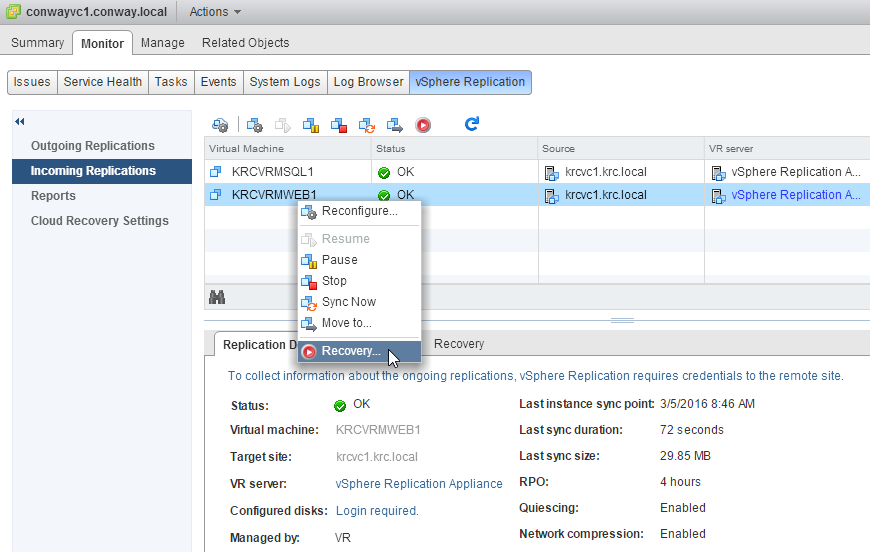
Because I cannot turn off the VM on the source location at this time, I’ll be recovering with the “latest data available” as shown below:
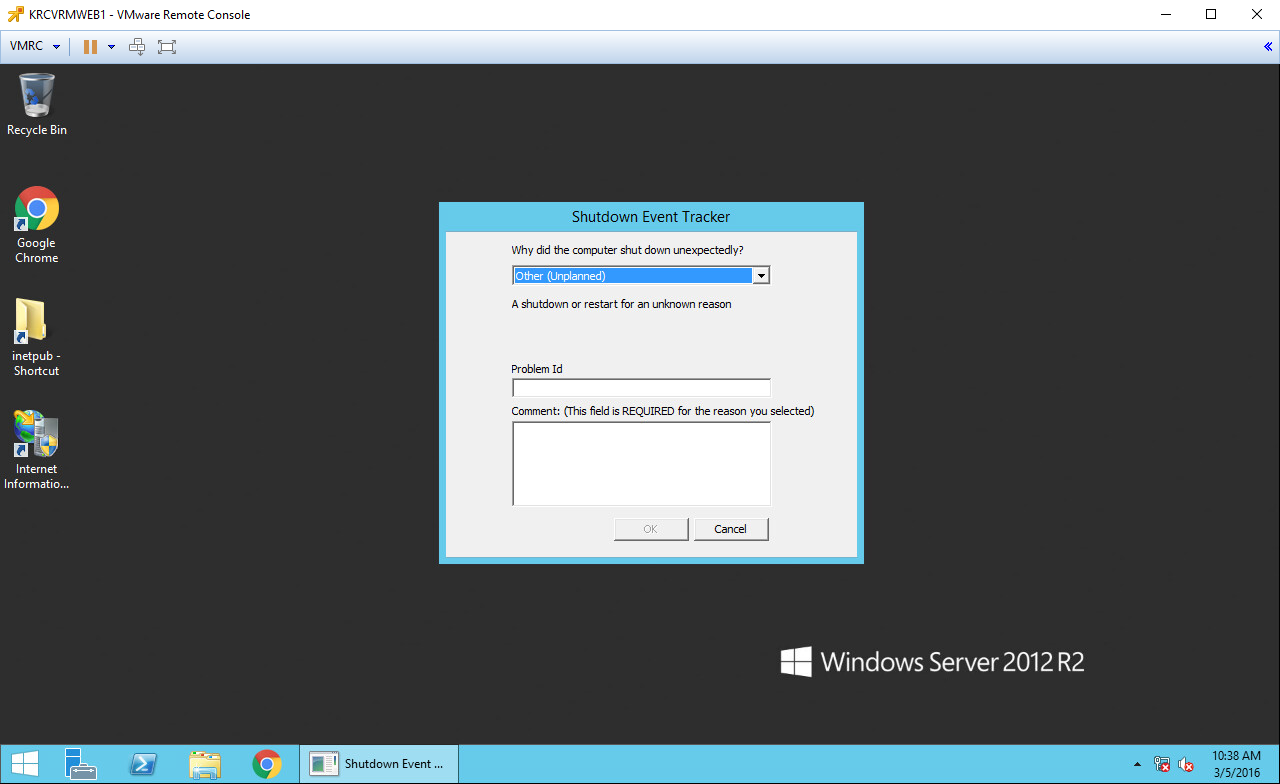
I will skip several arbitrary steps after this menu. Instead, I’m jumping to the VM booted up. You’ll see that it boots and indicates that it has been shutdown improperly – this is to be expected:
Now, let’s create a bunch of junk on the desktop so that we are certain we’ve modified this recovered VM in some way. Remember, we’re doing this on the destination side, so there’s no way that changes can be replicated back to production (because vSphere 6 doesn’t support destination to source replication after recovery):
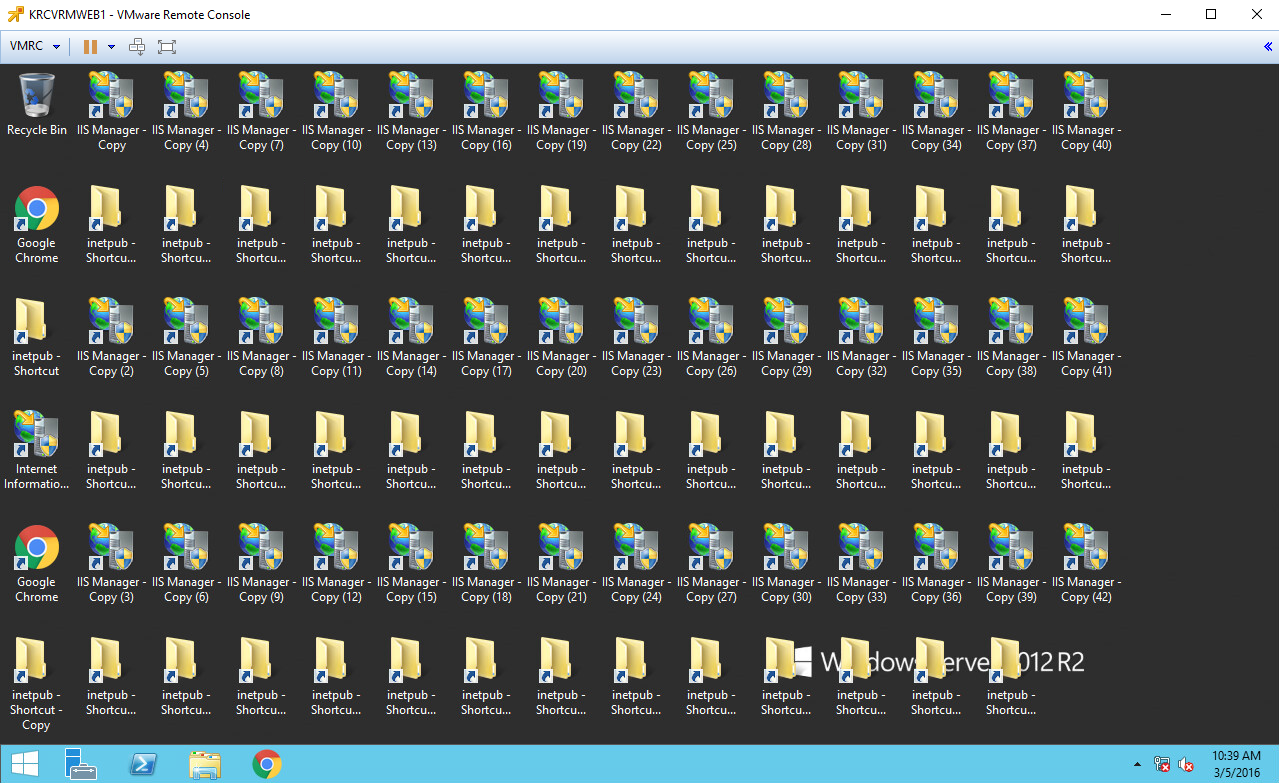
So, I’ve simply copied and pasted a ton of shortcuts over and over. Not a huge amount of data change, but we won’t be able to miss that when we go to test re-recovering the VM, right? A real recovery test might include re-IP’ing the VM, configuring DNS, etc. We won’t be doing that for this test but it’s definitely an option. Next, we shut the VM on the destination side down and Remove from Inventory:
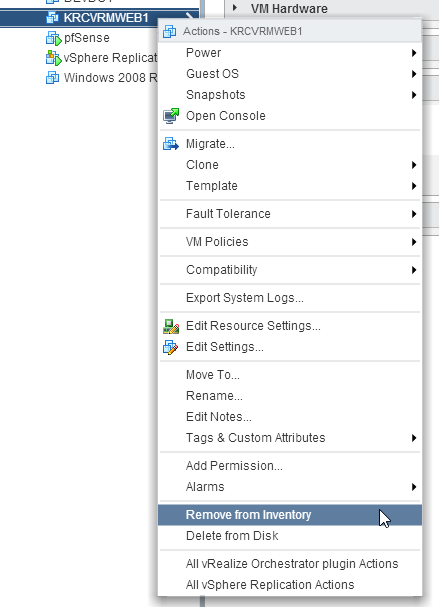
It’s very important that you do not choose Delete from Disk. If you do, you can kiss all your replicated data goodbye and will have to replicate the VM from the start all over again. Maybe that’s what you want, but if the VM is large I definitely want to avoid that at all costs. After you’ve removed the VM from inventory on the destination vCenter, go back to the source vCenter and Stop replication on the VM:

So we’ve stopped replication, but what does the destination datastore look like? Let’s find out – navigate to the datastore you were replicating to and browse the folder for the VM:
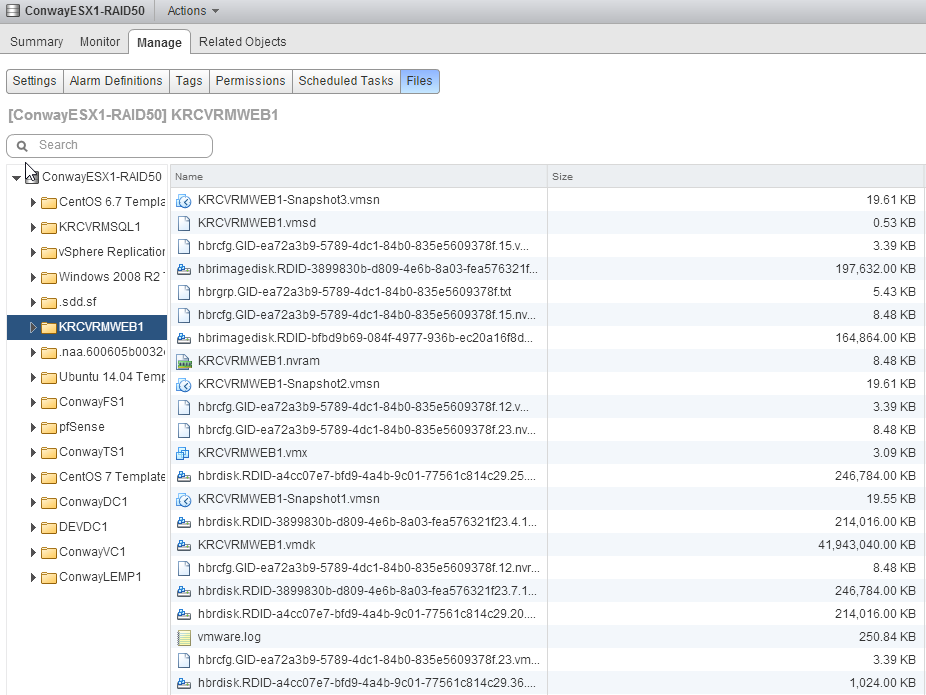
Above, you’ll notice that we have the GID, RDID, etc. files that are associated with replication but we also have a .nvram file and .vmx – that’s because we promoted the replica to a VM and thus these files were created. No big deal.
Now, right-click the VM on the source vCenter and reconfigure it for replication:
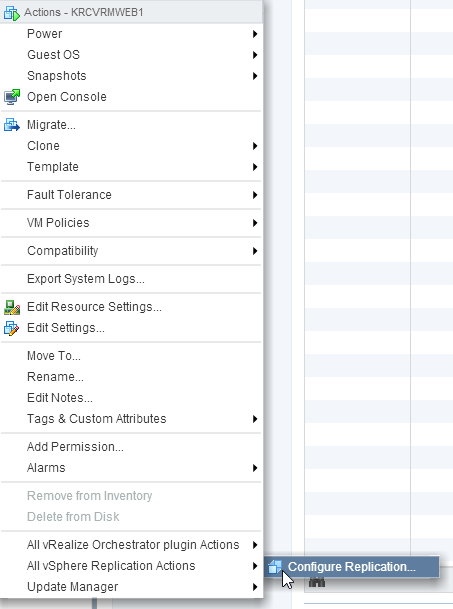
Once you step through the dialogues for configuring replication you’ll have to edit the datastore location for the replication of the VM and it should find that there is already a folder with the VM name present:
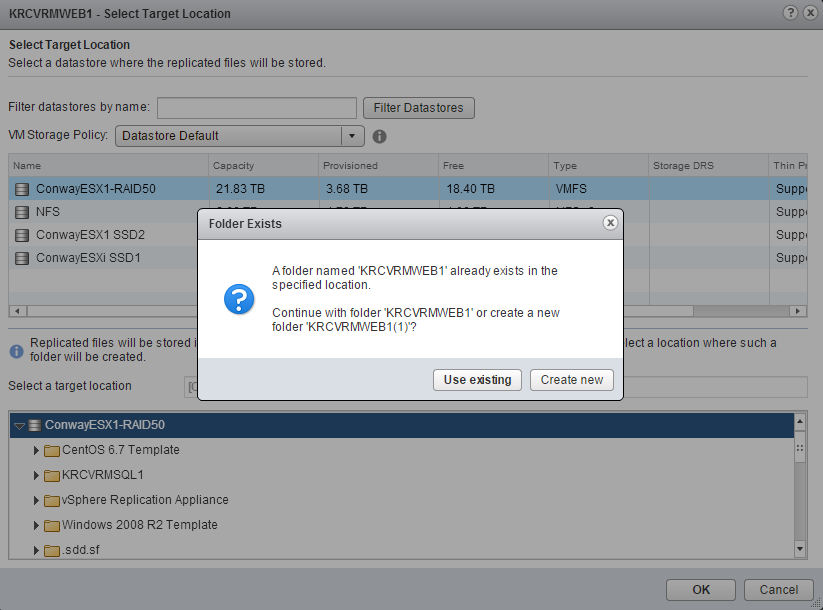
Of course you’ll want to choose Use Existing.
After you progress through the dialogue above, vSphere Replication will try to figure out whether or not there are any usable seed files in the folder you’ve placed the replication in. Since we’ve replicated this previously, there should be seed files discovered:
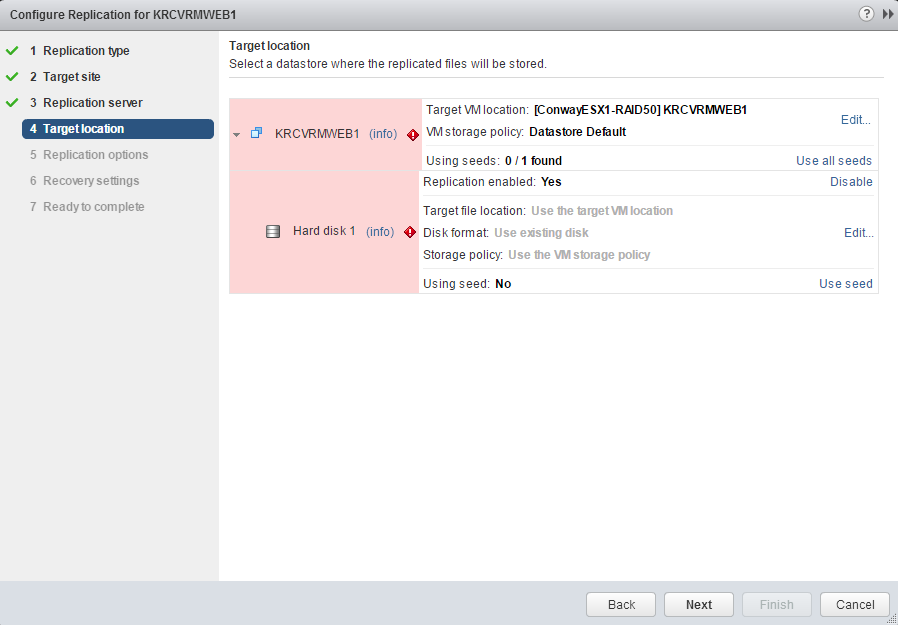
Once you click the Use all seeds option, the frightening red boxes will disappear and vSphere Recover will indicate that you’re using seed files:

After you’ve progressed through the rest of the replication dialogues replication should finish its configuration successfully. The next thing to do is check the replication status and you’ll notice something interesting:
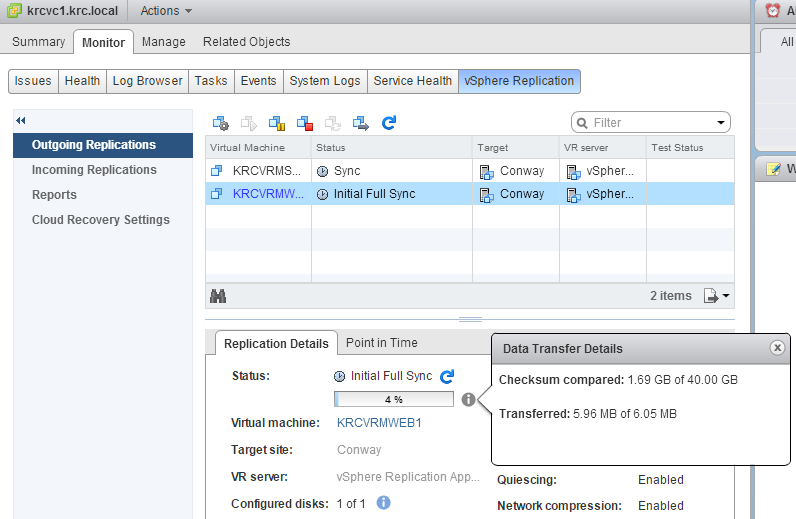
In the image above you’ll notice that there’s 40 GB of data that needs to have its checksum compared, but that there is only 6.05 MB to transfer. This is vSphere 6 utilizing CBT (changed block tracking) in order to figure out what’s different and same between the VMDKs that exist on the destination as compared to the source. So, since we recovered this VM and made a few changes to arbitrary data, there’s not a lot of data that’s different in the checksum for CBT. So, vSphere Replication 6 decides how much change has occurred and what needs to be re-replicated in order to get the two sides to match (obviously the source side is the primary). This checksum comparison can take a little while.
So, rather than replicate the entire 40GB VM again, we only need to replicate about 6.05 MB (this is an estimate because the checksum comparison had only run through 1.69 GB of 40 GB). This is an awesome time saver!
Let’s recover the VM on the destination side once more and see if all of the theoretical concepts above actually work. One thing you may recall from earlier is that we never did anything with that .vmx file in the folder. No worries, when you recover the VM and get to the portion where you select the cluster/host, you’ll be notified:

If you just click Next through the dialogue above and continue on, you’ll be prompted:
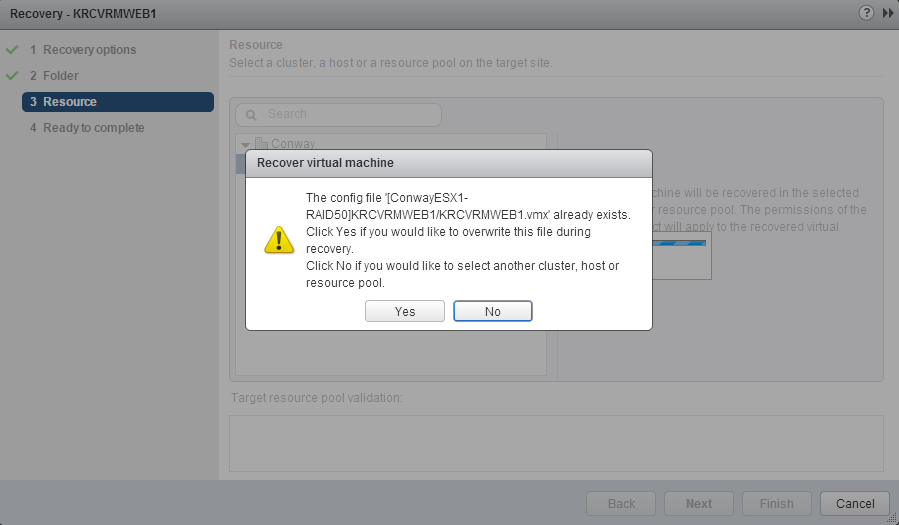
Obviously click Yes. We want to overwrite the .vmx file. Alternatively, you could browse into the folder where the replica was recovered before and delete the .vmx but there’s really no reason to.
The recovered VM should once again boot up, and we should see the icons we left all over the desktop, right?
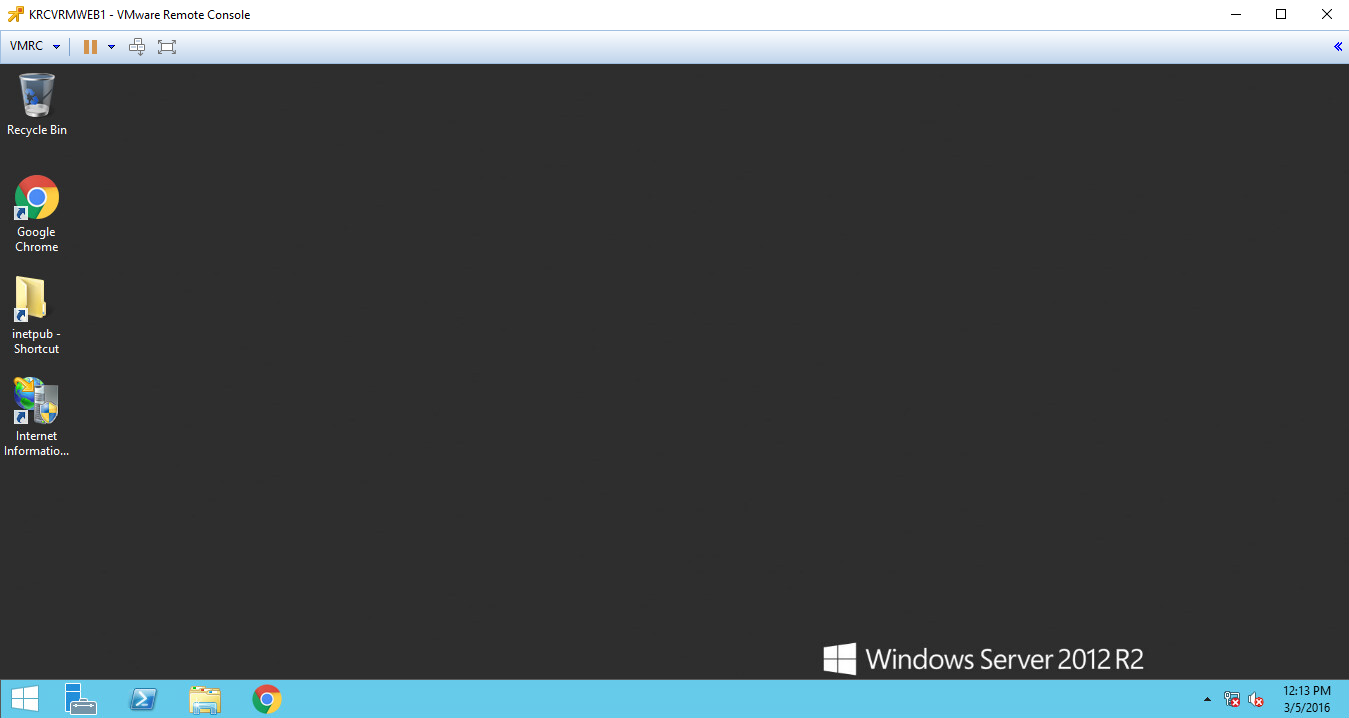
What happened to all of our ridiculous icons? That’s right – we re-configured replication and the replication tracked the changes to the VM and manipulated the blocks such that the VM on the destination now matches that of the source side again!
This is a real time saver whether you’re testing DR or replicating as part of a migration. Whatever changes are made on the replicated VM in order to do testing will be lost and overwritten by the source information. Hopefully you all find this useful!
 I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog!
I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog! 

July 5, 2017
Thanks for this guide…helped me just test DR for a site I look after (Used to Hyper-V so always nice to have a guide to follow). So important to make sure this stuff actually works rather than trust it…
June 14, 2017
Good tip thanks. I wish they would build a “re-protect” option in the tool so it would make testing easier. If you buy SRM licenses you can do testing but I don’t want to deploy SRM in some of the smaller environments I use vSphere replication in.