
Many of you have probably seen me talking a lot about my Lenovo TS140 ESXi build and here I am doing it again but for good reasons! The first rounds of discussions were about the original system with some tweaks making it a really capable ESXi host with tons of storage and a good amount of memory. I am endlessly impressed that Lenovo was able to deliver a solid littler performer for around $299 (base).
When I order a system from a company like Dell or Lenovo, and it’s pretty rare that I do since usually build them, I will order the fastest/best CPU I can afford and skimp on the memory as CPUs are generally expensive to buy separately. I do this because I can almost always get the amount of memory I’d like after the fact for much cheaper than Dell and others sell when shipping. So, naturally, when I discovered the TS140 for $299 came with a single 4GB DIMM I was elated because it meant I wasn’t paying for memory I wasn’t going to use (because I knew I wanted to go to 32GB for my purposes). The only item I wish I could have specified higher than base was the CPU. Don’t get me wrong, the TS140 as-shipped for $299 comes with the Intel Xeon E3-1225v3 which retails for about $220 – $235 from all of our favorite sellers. So, for $65 more I get the rest of the system! However, I would have probably paid a few dollars more to get a different CPU.

Intel Xeon E3-1225v3
The E3-1225v3, which features a base frequency of 3.2 GHz with turbo up to 3.6 GHz and 8MB cache, only falls short by the number of threads it offers and is excellent in every other way. The E3-1225v3 is a 4-core, 4-thread CPU as it offers no hyper-threading. For anyone who doesn’t understand hyper-threading, feel free to check out this wiki page on it. Consider again that my goal is to build a capable ESXi host with 32GB of RAM… hyper-threading will aid in resource scheduling. The reason for this is because every time I schedule a multi-core VM it will be scheduling against only 4 physical cores (and thus 4 logical processors) while using the E3-1225v3.

4 Logical Processors – No Hyper-threading
There’s nothing really wrong with this, but the way VMware makes clever use of resources means that without more logical processors some of my VMs will be scheduled to transact and perform computations against the physical CPU while other VMs are also looking to do the same thing. The end result? CPU Ready time. Again, this is not a problem so long as you are not over-committing your CPU beyond what is reasonably feasible. What’s reasonably feasible? Well… glad you asked.
Everytime you create a VM you are scheduling shared resources between it and other VMs, as well as the ESXi operating system itself. Anytime you have more vCPUs assigned to VMs than you have logical CPUs within your physical CPUs, ESXi will tell VMs to wait their turn to process information. If you have 4 logical processors to use and create a single VM with 4 vCPUs, there will be no waiting. If you create two VMs each with 4 vCPUs then the two are going to have to wait until the ESXi operating system has allowed for VM2 to compute while VM1 pauses. The time that any VM is spent waiting, ready to process information, is called CPU Ready Time and is measured two ways – %RDY (from within esxtop in SSH) and “summation” (measured in milliseconds) when monitoring a VM or host from vCenter. VMware basically says that for ideal performance CPU Ready Time for any given VM should not be much over 5%. They do recommend that you pay attention to the core-count of the VM as the CPU Ready Time will scale with CPU allocation, but in general, <5% is where you want to be. As you approach 10% you should understand that your VMs are waiting more (and thus performing worse) and, obviously, going over 10% further is just going in the wrong vector.
So, maybe creating 8 VMs with 4 vCPUs each while using a single 4-core CPU isn’t such a hot idea if you expect top performance. I know what you’re thinking, “But my VMs are not under high CPU load% so I am not worried about it!” I hear this a lot and absolutely understand why you might be inclined to think that way. You must understand that this whole conversation does not mention CPU load% at all and I will only reference it later to prove a point. A VM, whether its pegging the CPU at 100% or idling at 2% is using resources – resources that are scheduled (it is no mistake that DRS in ESXi stands for Distributed Resource Scheduler). There is no such thing as sleep mode for a vCPU – even if you let a VM sit alone in a dark corner of the universe and completely ignore it. The VM still has internal clocks and counters to account for how it “thinks”. If you are familiar with physical CPUs you might know about core parking but that doesn’t apply here as you cannot park a vCPU (nor would you want to).
Think of it like this: If you invite 4 families of 4 over for a buffet dinner it doesn’t really matter if they’re hungry or not, they’re going to occupy seats. You’re going to need to take their jackets and scarves and put them away. You’re going to need to have enough plates, glasses, silverware, etc. The families all get up and in groups of 4, together, and check out the buffet as a pack, and so everyone behind them will always be waiting for 4 people to finish perusing. If you invite only the couple or single person from that family you are friends with or talk to, well, that makes everything a lot more efficient, doesn’t it?
Conquering CPU Ready Time by understanding it!
Instead of scheduling these wide, high core-count VMs, you might be better off scheduling many single-core VMs. The reason for this is that the vCPUs, though not physically tied to anything, try and make the best of NUMA and linking physical architecture of a processor to virtual workloads. So, if you understand nothing else, understand that a wide, CPU-heavy VM is going to generally be scheduled as such – many cores at a time. That means a nice fat 4 vCPU VM is going to hog the food at the buffet line and keep that 1 vCPU, lightweight VM waiting for its turn. And, remember, it doesn’t descriminate – it makes any VM wait, not just the lightweights. The inverse is true too – that big 4+ vCPU VM is also going to wait until there is enough room in the schedule to work. You can see how this can get complicated. Generally speaking, high vCPU VMs tend to exhibit higher CPU Read Time than smaller ones on over-allocated clusters.
One other thing worth mentioning that doesn’t exactly apply here since I have only one CPU socket in this host is that you really want to avoid scheduling vCPU in methods that do not match what the logical processors NUMA look like. So for instance, if you have two sockets in your server and have two 6-core Xeons with hyper-threading active, totaling 24 logical processors in the single host but only 12 logical processors per socket, try to not create 16 vCPU VMs. Remember, the resources are scheduled with NUMA in mind, but the only way you can schedule 16 vCPUs in this situation is to use some portion of logical processors on one socket combined with some portion of logical processors on the other. Now you’re complicating the scheduling big time because no matter what you can never schedule 16 vCPU of one VM on one socket at once because it requires the other socket to have free scheduling as well. This will increase your CPU Ready Time significantly. That’s not to say you can’t do it – you can. In fact, you can go bigger. But the point is when you are scheduling resources you really want to try to not exceed in one VM what one socket can support in a populated cluster/host.
So, what do you do if you have a need for the many 2-, 4-, even 8-core VMs you’ve painstakingly created? Well, you either cut vCPU allocation back or you add hardware. The first option is free and the second option is not – most of my clients prefer the first option. In my case, I am not running any VMs with more than 2 vCPUs but I want to be able to test more and more on my Lenovo TS140 without hitting my CPU Ready Time ceiling so soon. I know I have only 32GB of RAM to work with but the way RAM is allocated is much different than how the CPU Ready Time works. Plus, I can always run my Ubuntu and CentOS VMs on 512MB RAM if I needed. This is why, in my case, I added hardware:

Intel Xeon E3-1246v3

Intel Xeon E3-1246v3
Pictured above is the Intel Xeon E3-1246v3. This CPU is a little bit faster from a clock-speed perspective when compared to the E3-1225v3 which is always a bonus, but the big benefit to me is that the E3-1246v3 supports hyper-threading. The new CPU is a 3.5 GHz base clock-speed with turbo going to 3.9 GHz and has the same 8MB of cache as the former CPU. However, now you’ll find that my total logical processor count on my ESXi host has doubled from the previous figure:
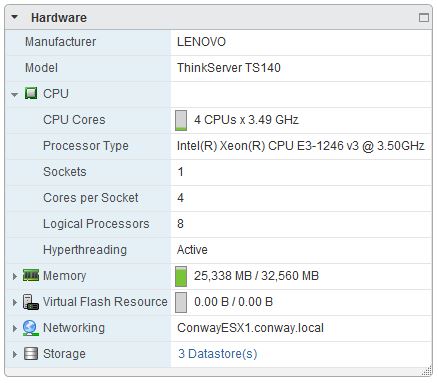
8 Logical Processors – Hyper-threading Enabled
So now, with 8 logical processors I can literally double my allocation of CPU while maintaining the same (or similar) CPU Ready Time. Or, maybe a better way to go is having the ability to cut my CPU Ready Time in half while maintaining the CPU allocation I have and experience more performance from my existing setup. You’ll notice that the memory used in the screenshot above (from the vCenter Web Client this time, sorry) indicates I am running a lot more VMs or am running more RAM in the VMs. The truth is, I am running more VMs. I don’t remember what the VM count was in the earlier screenshot but I think it was 10 or so. I am now running 14 VMs actively with 6 additional test VMs turned off because I have a VM with a large amount of RAM allocated. With the addition of the E3-1246v3 I am now able to run much more liberally with vCPUs allocated without worrying too much about over-allocating the host. But, how do we know if anything improved? Simple! Performance monitoring!
In order to see what difference the new CPU made we just go over to the host in vSphere and select “Monitor” and run a quick query on performance statistics based around the CPU use. It is important that we click the “Advanced” tab and then “Chart Options” and make sure “Ready Time” is selected. You’ll notice I am selecting “Usage” too – this is the CPU load% of the host. Remember I told you I was only going to do this later on to prove a point? Here it comes. I am running the report for the last 1-month:
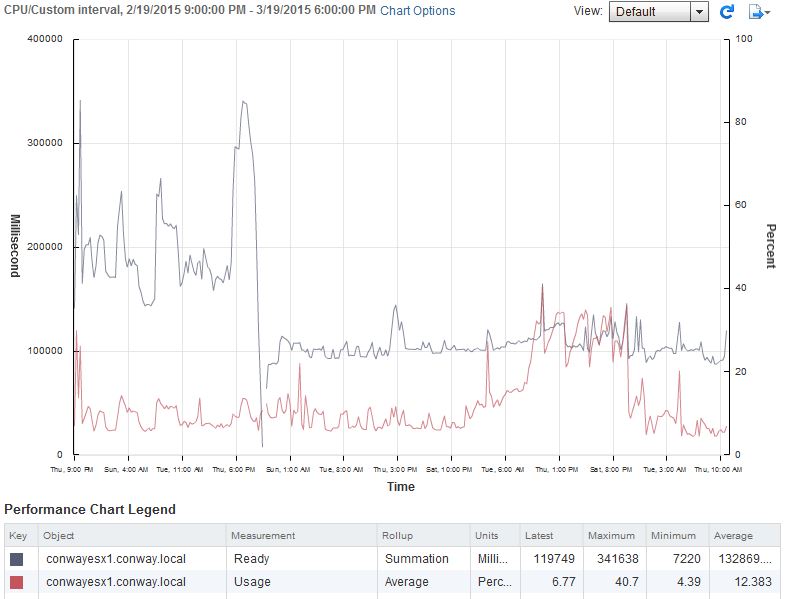
CPU Ready Time Chart
Take a look at that for a second and note that the black line is the “Ready” time (in summation, milliseconds) and the red line is “Usage”. This is for the host as a whole, not any given single VM. That huge plummet in CPU Ready Time is attributed, absolutely, to the installation of the new CPU. You will see that from the beginning of my chart to about 2/3 across the CPU Usage doesn’t change at all really… yet CPU Ready Time dives way down, approximately in half… Wait! We doubled the logical processors, CPU Ready Time cut in half… wow, science!
Right. So sarcasm aside you can see that as the chart progresses across the last ~30 days the CPU Usage goes up (because I am allocating more CPU and/or creating more VMs) but the CPU Ready Time really doesn’t move. Remember how I mentioned many people think that because their CPU is not under a heavy load% that they have a healthy, ideal running environment? Now you can appreciate it! I won’t bore you with how the conversion of Summation (milliseconds) to CPU Ready Time (%RDY) works, you can go here to do that equation for youself. But, note that I ran the chart for the last month, and if you follow that link you can find the update interval associated with that. If you math it out the average load for the last 2/3 of that chart comes out to about 1.5% using an update interval of 7200 seconds. Using the same update interval and calculating the first 1/3 of the chart, which was running on the E3-1225v3 CPU, you’ll get about 3.1 – 3.3%. REMEMBER: This is for the host as a whole. Remember that VMware suggests < 5% CPU Ready Time for any given individual VM.
You may want to see if you have any outlier VMs with high CPU Ready Time so that you can assess further. The best way to check actual %RDY is by enabling SSH on your host and logging in via Putty using your root credentials. Once in, you can issue the esxtop command (very handy for any ESXi administrator!) and then you can press SHIFT+V to display only VMs in the list. There’s a 2 – 3 second refresh rate in this view but this is a realtime idea of your CPU Ready Time. The column you’re most interested in is %RDY:
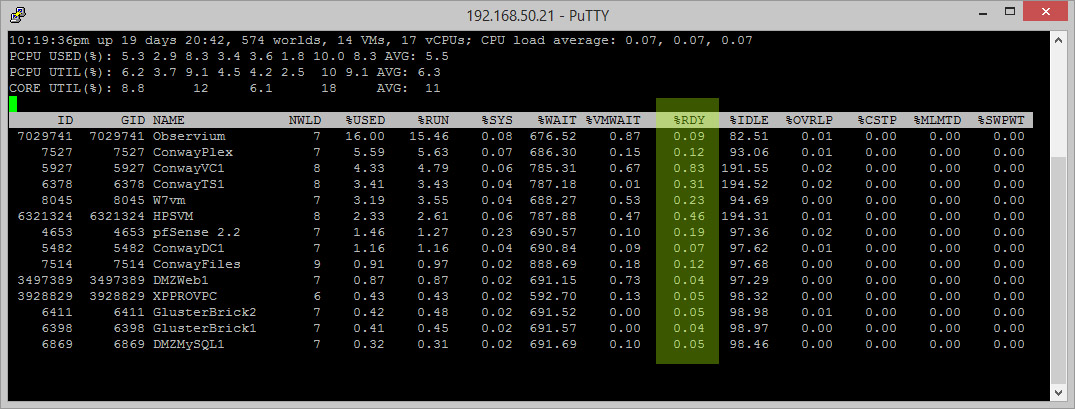
%RDY shown in esxtop
Again, the view above is instantaneous for the %RDY figure and will change a bunch while you watch. However, should you have a problem going on it’ll be obvious. You won’t really notice anything severe until you’ve over-allocated your logical processors to about 2.0 – 2.5x or if you have created a high number of VMs with many vCPUs allocated, specially if the vCPU allocation differs from the logical processor count per socket as mentioned above. As an example here is a screenshot of an environment I was troubleshooting. This is not the highest %RDY figures that were showing throughout the period of troubleshooting, either:
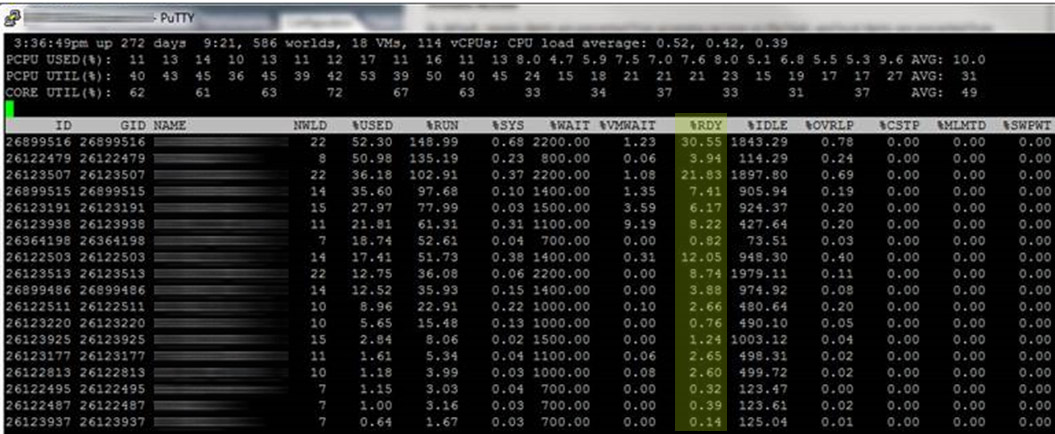
High %RDY Time
The environment pictured above has really good hardware in place with really good storage and networking components, but the client complained about performance of several specific VMs along with our monitoring solutions showing timeouts and long response times to certain tasks within the network (at the layer 2 level) which is indicative of trouble with resource scheduling. Sometimes clients will deploy their own VMs without any suggestion or assessment which can lead to an environment becoming over-allocated.
A quick esxtop on each of the hosts in this cluster (after a host-wide report which helps us zero in on where issues might be) paints the picture clearly. Remember that VMware recommends < 5% %RDY when possible for the best experience. These VMs well over 5% and you can see the top one at 30.55% – this number fluctuated all the way up and over a %RDY value of 57%! An assessment of the environment was done, resources were dialed back on over-sized VMs, and the numbers improved greatly and the VMs perform much, much better with no hardware added. The best way to dial something like this in is to load test applications and tune the vCPU allocation exactly as needed. Once you’ve backed yourself into those figures you will realize you either have over-sized VMs and can schedule them better, or you know that there’s nothing you can do and need to either upgrade physical CPUs or add more of them, which will likely involve additional ESXi hosts.
A long read, but practical and good knowledge! I hope you find this entry useful!
 I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog!
I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog! 

November 18, 2016
Thanks John and Nick. This thread is still relevant. I purchased a TS140 with i3-4130 for $180 earlier this year. I found my MB FRU allows for the upgrade to the E3-1246V3. Finally, an upgrade I’m looking forward to.
My setup:
i3-4130
16GB Kingston HyperX non-ecc
Avago 9265-8i (2x 512GB Vertex4 ssd-R1, 4x HGST 3TB-R6)
Zotac 1060 mini 6GB
Corsair 500 PSU
Windows10 (looking for update to KVM/proxmox, maybe)
September 11, 2016
was there a slower 6 core CPU with Hyper-threading you could have used?
April 18, 2016
Hi Jon,
I am curious. What is the model number of your TS140 motherboard? I have a TS140 and want to upgrade it like you did to the E3 1246V3. However, back in late 2014, Lenovo warned that Haswell Refresh CPUs (like the E3-1245V3) may not work in all TS140s https://support.lenovo.com/us/en/documents/ht100738?tabName=Solutions
However since then, new BIOS and new ME firmware has been released so I am hoping that the E3-1246V3 will now work in my server.
If I can find out what your TS140 motherboard’s FRU/model number is it will help me to decide to go forward with an upgrade similar to yours.
Thanks Nick
April 14, 2015
Dude – can you hook me up with your ts140 esxi5.5 iso installer PLEASE !
I have a surface pro – with no room to install tools to customize the image – and no time…
Appreciate it if you could help me out!
Thanks – Chris
May 1, 2015
I’d love a copy of this ISO as well – was about to build a home lab and this would be a good cheap model for me to work with.