
Keep it simple, stupid.
One of the things I’ve been working on is cleaning up and consolidating my virtual environment(s) (both at work and home). It’s very easy to start building and testing things and before you know it, you’ve got stuff all over the place. One of the things that I was testing ended up becoming something I (and you, if you subscribe to my site) relied on – my GlusterFS-backed web farm.
Originally, I had two web front ends running NGINX (I prefer it over Apache these days) and utilizing the proxy_pass feature for round robin load balancing right from within the server block file. I initially deployed this setup using a third webserver as a load balancer two the other two web front ends, but this meant that I had 3 VMs powered on. One I realized I could slip the load balancing config right into the server block (aka virtual host file) I was able to eliminate that third server. Because my primary ESXi host in my lab has only 32GB (maximum supported), I need to be cautious and deliberate when creating VMs (shouldn’t we always be, though?).
My usual “general purpose Linux VM” is configured with the following:
- Ubuntu 14.04.2 Server
- 1 vCPU
- 512MB RAM
- 16GB primary disk
- VMXnet 3 NIC
Pretty simple! However, you may have noticed above I used the term “web farm”. That’s because I had been testing and ultimately ended up using a GlusterFS back end for my web front end. The reason for that was because at the time I only had a RAID50 storage pool and a single SSD in my ESXi host. I wanted my websites (and databases) to load as fast as possible, so that meant putting the sites and databases on SSD. However, there was no redundancy at all with a single SSD. So, I got around this by creating a clustered filesystem with one Gluster brick on SSD and one on RAID50. The primary was on SSD but if that went offline then the content would be pulled from the second brick on the RAID50 pool. It worked well for about a year or so with only one issue – one time when rebooting the web front end it came up and couldn’t connect to the GlusterFS. A simple reboot and mount -a fixed that.
The problem with this setup is that it significantly increases the “web farm” utilization of resources. My websites are mostly low volume – I run one forum (www.dtaforum.com) that does get a decent amount of traffic. When I share new posts and findings on various social media outlets this blog will get hammered for a bit but overall it and about 10 other sites I run are low volume. If you were to host all of theses sites off of a VPS or shared host you’d be able to do it on a decent shared host or VPS with 1 vCPU, 1GB of RAM, and enough disk. Instead, I had two Gluster bricks each with 1 vCPU, 512MB RAM, 80GB disk. Then, on top of that, I had (at one point) two web front ends with 1 vCPU, 512MB RAM, and 16GB disk. Finally, there was a single MySQL server with 1 vCPU, 1GB RAM, and 20GB disk. So, in total, I had 5 vCPU assigned, 3GB of RAM, and 212GB assigned with 100GB of that being on SSD (850 Evo 250GB). Not very economical but it was good to learn how to use Gluster and load-balancing, etc. In the end, I took out one web front end as it really wasn’t doing a whole lot – here’s what it looked like:
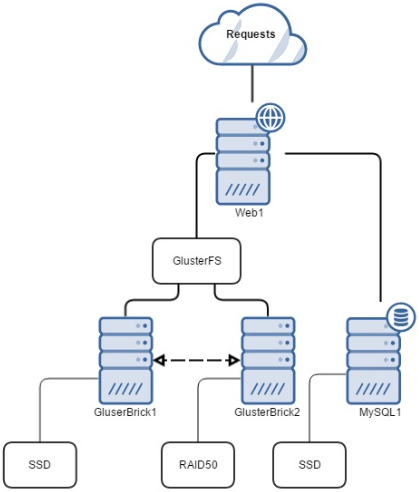
As I play with more VMware products (Orchestrator, linked vCenters, VDP, vRealize Operations Manager, etc.) I found my host becoming short on RAM. A quick way to pull back my assigned CPU and RAM is to clean up this web farm. I made a pretty significant change (for me) – I consolidated all of the VMs involved in the image above into a single VM, changed server OS, and kept the speed of the SSD tier but with the redundancy of the RAID50 tier.
First things first, I know you’re wondering how we accomplish the best of both worlds on the storage front. Well, I had been testing a few different solutions. I was going to buy a SAS expander and add the SSD right into the LSI 9260-8i’s array but realized I would probably need to spend on licensing also. At the same time, I had been testing VMware’s Virtual Flash Read Cache in my lab and saw great results with that. Instead of using my SSD as a datastore location for various VMs, I svMotion’d all of my VMs to RAID50 and then dedicated the entire SSD as cache once it was vacated. The drag with Virtual Flash Read Cache is that you have to use an entire SSD and cannot assign only some of it. The benefit of Virtual Flash Read Cache is that it is assignable per virtual disk so rather than have to commit each virtual disk to an SSD datastore, you can assign (in GB) how much cache a virtual disk should have. Check out this link for more information on vSphere Virtual Flash Read Cache. Here’s what it looks like configured:

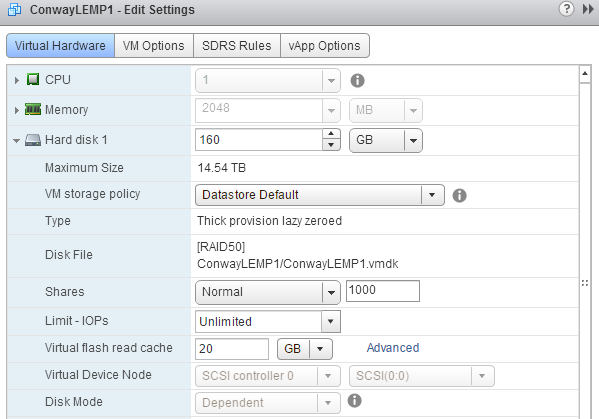
So, because my web server/mysql server rely on 99% reads this is a fantastic option. As mentioned, it lets me assign SSD cache to other VMs that I probably wouldn’t have put on SSD. You must know, though, that writes are “write through” to the primary datastore of the virtual disk. So, as I create this blog, the content I upload goes to the RAID50 pool, not the SSD. That’s fine, though, because I have a write-back cached RAID controller so my performance is great on writes anyway.
The other significant change is that I jumped ship from Ubuntu. Actually, I haven’t jumped ship, but I am extending my Linux use over to CentOS. I used to administer about 5-7 Red Hat Enterprise Linux 5 servers (physical) at a former job. They were pretty reliable overall and didn’t take much messing with, though – just updates and such. I can stumble around pretty well in RHEL/CentOS 6, but we’re utilizing RHEL 7 and CentOS 7 more and more at work where we barely use Ubuntu/Debian at all. I think I picked up Ubuntu back in the 9.x or 10.x days and used it because there were more tutorials and guides than for other distributions. Now that I know what I need to do, and how to do it overall, I am switching to CentOS 7 for my Linux needs. I won’t get in to what is different about CentOS 7 but its different enough from my RHEL 5.3 (and obviously Ubuntu/Debian) days to need to re-learn.
So with that said, my “web farm” is down to one single VM running CentOS 7. The VM utilizes 1 vCPU, 1GB RAM (despite the earlier screenshot showing 2GB), and 160GB of RAID50 storage but the VM has 20GB of Virtual Flash Read Cache enabled through vSphere 6. I’ve cut my vRAM use to by 66% and my SSD storage use by 80% all while increasing the redundancy of the storage itself – not bad! A lot of people may say “Yeah but now it’s just a standard LEMP server – GlusterFS is cool!” and I agree. It is just a simple LEMP server, which is what most people start with when setting up websites. And, GlusterFS is cool, but as my homelab grows I need to reign some things in and this consolidation is a free “upgrade” in terms of gaining back memory, CPU, and precious SSD space.
Thanks for reading!
 I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog!
I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog! 
