
So I was playing with the ability to subscribe to a vSphere Content Library in AWS S3 today and found it to be really, really cool. I followed Create a vCenter Content Library using AWS S3 by Gilles Chekroun and had it up and running in no time. I’ve also read posts by William Lam such as his article titled External replication of vSphere Content Library. On my way home this evening I was listening to the Virtually Speaking Podcast where Myles Gray speaks to his excitement about customer feedback containing suggestions and requests along with “what you’re doing is exactly what we want to see” type stuff.
To get even more meta and referential, I started thinking about something I’ve had on my mind now for a few days. A while back I had the opportunity to speak with the team behind the Content Library project then headed up by Pratima (Rao) Gluckman. After signing some stuff, things we discussed with the team and expressed wanting to see eventually did come to the solution (engaging humility, I am certain more customers other than myself voiced these suggestions). Unfortunately my discussion with the team followed my moderately critical blog post on the topic. Anyhow, I was really excited and motivated by the whole ordeal because it became apparent that not only does VMware read user blogs, but they reach out and try and understand our needs.
One scenario I described to the Content Library team was that of a service provider or large company who may manage or run many instances of vCenter that may or may not have connectivity to one another. While there is the option to publish a Content Library externally across WAN I had (and still have) reservations with this. Further, when setting a Content Library to be optimized for syncing over HTTP you cannot deploy VMs. Another issue is availability and latency – if my primary vCenter is in Philadelphia, PA it’s going to be rather brutal to sync a large template/OVF to San Francisco, CA. That’s where the AWS S3 comes in.
While the article by Gilles Chekroun talks about subscribing/syncing from an S3-based Content Library my idea involves just the opposite. What if you could publish/sync to an S3-based Content Library repository?
This post is going to be the first of a category I am going to consider “vThinking Aloud” – basically ideas I have that might pertain to all things cloudy and virtualization for better or worse. Maybe they’re cool – maybe they stink – either way, I am going to start sharing them in this manner because hey, why not?
Why do this?
Remember my concerns about availability and latency? AWS S3 can help us get around this quite easily. S3 supports Cross-Region Replication (CRR) – this provides a native method of replication from, say us-east-1 to us-west-2 without any form of external replication. While S3 is an “eventually consistent” object store we don’t need rapid replication of changes because we’re talking about templates and ISOs, etc. that we need to have available across multiple data centers and vCenter instances. The benefit here would also be that you could leverage S3 storage costs, syncing only the items you require in the pertinent subscribed Content Library as needed.
This is different from what Gilles covered because right now you need to maintain the S3-based Content Library with a python script that generates the json files that keep track of the metadata for the Content Library items. If we could natively publish to S3 (from within the vSphere Client UI, AWS S3/vSphere API in the background) and then leverage CRR, we could feasibly subscribe vCenter servers to the Content Library that are placed as close (geographically) as possible to a given S3 bucket containing replica data. Further, we would be able to maintain the Content Library from within the vSphere client as opposed to mirroring the file structure and running the python scripts as above.
Do you manage clients with vCenter servers in the US and Europe? If you do, then you know that getting templates to and from is a huge pain.
How could it be done?
This wouldn’t be that hard, in theory. Additionally, I can think of a few ways we could make it more secure as well.
First, both S3 and vSphere have APIs that support this functionality. The necessary vSphere APIs may not be exposed, but they’re there, obviously. If for some reason the APIs cannot present the functionality needed, Photon OS (VCSA) supports python2 and python3 so the existing script can be adapted to take care of some additional functionality if required (more than likely not necessary).
The current concept in the article above requires making a given S3 bucket public which may be fine for vanilla OVF templates or ISOs, but what about things that are proprietary? No worries – we can leverage awscli on Photon OS (VCSA) or through APIs to handle AWS credentials. We can then utilize AWS IAM Access ID/Secret Key to secure the contents of the “published S3” library. In the example of the subscribed Content Library you need to configure credentials for the python script to connect to the S3 bucket and create folders/files. We could leverage this same methodology while also introducing the credential (or another) in order to read from the bucket thus securing the contents. Perhaps you would have a rear-only credential and a full-access credential. You get the idea – publishing vs. subscribing credentials.
The concept of securing the S3-based published Content Library would allow us to then subscribe additional, perhaps out-of-domain Content Libraries to the S3-based published library. This means in the case of a service provider I do not have to utilize Linked Mode in order to do VM deploys from the Content Library – this eliminates many security concerns, costs, and complexities involving VPN configuration, etc.
Another huge advantage to leveraging S3 as a published Content Library location (maybe the word is repository?) is that we can configure not only Cross-Region Replication to get our data closer to where it’s needed, but we can also configure Cross-Account Replication. Cross-Account Replication would allow, for instance, a service provider to manage templates, ISOs, and OVF files but then also provide a replica to buckets owned by another AWS Account ID (via access/bucket policies). This would be extremely flexible in that you could control who is paying for the storage of data if need be or you can provide “Content Library as a Service” (CLaaS, claimed it!) and specifically allow clients to subscribe to your repository! Maybe you require a certain storage tier because your S3-based Content Library is the source but a client may have internal policies to store this data on One Zone-Infrequent Access tier. You get the idea – let them handle that part.
If we can utilize guest customization with the S3-based Content Library templates then we can use the same template in multiple clients/and apply different Microsoft Keys, hostnames, passwords, etc. to the deployed VMs as needed in each vCenter. If you want to get hyper-hypothetical, wouldn’t it be cool to leverage S3 versioning to do something similar to Linked Clones? Let’s not get too far ahead of ourselves here.
Dealing with SOX, GXP, HIPAA-based Content Library data? Maybe you set up archival policies to keep track of templates. If a template was deployed 7/25/2018 maybe you roll a copy of the template into AWS Glacier at the end of each month for auditing purposes to know what was deployed.
Going further, while leveraging S3 for all of this we can start getting into versioning of templates natively within AWS S3, encrypting the data, etc. I can think of a dozen or so use cases for this alone.
What does it look like?
I think this visual will be extremely self-explanatory. It’ll also show one of the more distributed configurations of this S3-based Content Library I can think of.
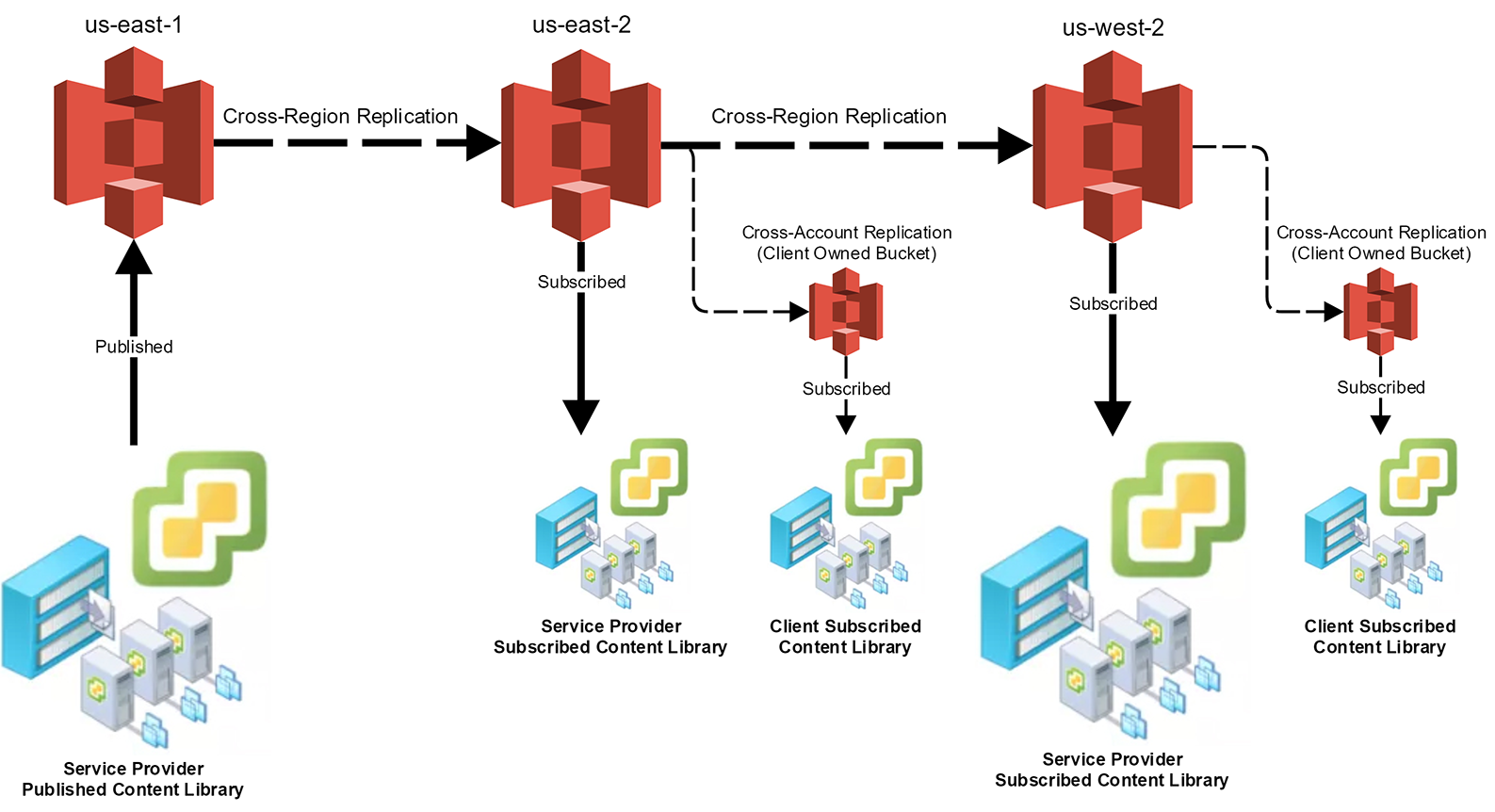
In the diagram above you can see that we have three regions at play including us-east1, us-east-2, and us-west-2 but we could also introduce eu-west-2, etc. You can see we could be leveraging Cross-Region Replication between these regions. If you look at the VMware icons below the AWS S3 ones you can see what represents a vSphere Data center/Content Library. The larger Content Library icons are “Service Provider-Owned” with the left-most being the primary “S3-based Published Content Library”. The left-most one is the “input” or source. From that Content Library the provider would control what gets inserted into Content Library using the vSphere UI. Once data is in the library, AWS replication takes it from there.
We’d need to leverage very similar json files as the original example article at the beginning of this post so that each replication resembles the structure and metadata that vSphere Content Library wants to see. Depending on the level of integration that might happen, the primary Published Content Library may even be able to make use of S3 storage for the original data, or maybe we just use APIs to copy and model the structure up in the original us-east-1 bucket.
The smaller Content Library icons represent “Client-Owned Subscribed Content Library” situations. You can see that in the us-east-2 location we have a Content Library that could subscribe to the replica S3 bucket, but then we could also Cross-Account Replicate the data into a Client-Owned S3 bucket and let them handle storage tiering and lifecycle policies on the bucket. We’d leverage the AWS Account along with access/bucket policies to control the access to the replica.
I didn’t bother to diagram it, but you could have an instance where N Content Library environments subscribe to the same bucket. These subscriptions could be owned by anyone who has a valid Access ID/Secret Key permission to the bucket – much more secure and controlled than buckets made public.
Finally, you can see that we have a replicated the original source S3 bucket from N. Virginia (us-east-1) all the way over to Oregon (us-west-2) so doing VM deploys or ISO mounts from vCenter servers in these different locations would perform better than sourcing form a single S3 bucket. We know that S3 is eventually consistent, so we need to allow time for the data to get to all of these locations. However, allowing AWS to manage this is your best bet because they’ve got all of the inter-facility connectivity in place already. Traditionally you would need VPN connectivity (or MPLS, etc.) between vCenter servers or leverage external syncing, etc.
Another item this takes care of is storing template data and ISOs. Have your templates on the same (or similar) storage tier as your production data? Yeah, most of us do. S3 is cheaper than Pure or Netapp, so there’s that added benefit, too!
So, that’s my idea. Nothing supremely profound, just taking the concept I was playing with today one step further. I think VMware might consider something like this especially with partnership they now have with VMware Cloud on AWS – you could extend your Content Library there as well!
Let me know what you think – if you think the idea is cool then let VMware know. If you think it doesn’t make sense or I am completely overlooking something, feel free to let me know that, too!
Thanks for reading!
 I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog!
I am a Sr. Systems Engineer by profession and am interested in all aspects of technology. I am most interested in virtualization, storage, and enterprise hardware. I am also interested in leveraging public and private cloud technologies such as Amazon AWS, Microsoft Azure, and vRealize Automation/vCloud Director. When not working with technology I enjoy building high performance cars and dabbling with photography. Thanks for checking out my blog! 

August 3, 2018
I prefer to solve such issues with the help of specialists who can give me clear answers to the questions that interest me.